текст перекладу
Це історія про те, як я вирушив у велике пригоди (яке зайняло набагато більше часу, ніж я очікував) з дослідження музики за допомогою моїх даних користувача Spotify.
Візуалізація Tableau.
текст перекладу
Для
``` ```
``` Приручення Spotify API: Подорож дата-сайєнтіста. У своєму прагненні аналізувати свою історію прослуховувань на Spotify я вирушив у подорож, щоб приручити Spotify API і витягнути цінну інформацію про жанри.
Це включало орієнтацію в складнощах автентифікації, API запитів та обробки даних у хмарному середовищі.
## Підготовка до роботи: Налаштування Spotify API
* Автентифікація: Я використав бібліотеку Spotipy для управління процесом автентифікації Spotify API. Працюючи в хмарному середовищі PythonAnywhere, мені довелося вручну проходити процес авторизації, копіюючи URL для авторизації, входячи в Spotify і вставляючи код назад у консоль. Щоб уникнути цього повторення, я кешував токен доступу для зручності при наступних запусках.
## Огляд Spotify API: Посібник для Data Scientist з аналізу жанрів
Моя подорож з аналізу історії прослуховувань на Spotify почалася з пошуку цінної інформації про жанри через Spotify API. Це включало подолання проблем з автентифікацією, API запитами та маніпуляцією даними в хмарному середовищі.
### Налаштування Spotify API
* Автентифікація: Я використовував бібліотеку Spotipy для керування процесом автентифікації Spotify API. Працюючи в хмарному середовищі PythonAnywhere, мені довелося вручну проходити процес авторизації, що включало копіювання URL для авторизації, вхід у Spotify та вставку коду назад у консоль. Для спрощення цього процесу я кешував токен доступу для подальшого використання.
* API Запити: Бібліотека requests була дуже корисною для взаємодії з кінцевими точками Spotify API /tracks і /artists. Я використовував пакетні запити для ефективного отримання деталей треків і кешував інформацію про жанри артистів, щоб уникнути зайвих API викликів. Крім того, я додав обробку помилок та експоненціальну відкату для вирішення можливих помилок API та обмежень на кількість запитів.
### Підготовка та трансформація даних
* Завантаження та очищення: Моя історія прослуховувань на Spotify, збережена у очищених JSON файлах, була завантажена та підготовлена для аналізу.
* Витягнення URI треків: Я витягнув поле spotify_track_uri, фільтруючи недійсні або недоступні треки.
* Отримання інформації про жанри: Використовуючи Spotify API, я отримав інформацію про жанри для кожного треку і зберіг результати у словнику.
* Створення DataFrame: Словник було перетворено у Pandas DataFrame, а також був створений окремий DataFrame для запису будь-яких не оброблених треків.
* Експорт у CSV: Наприкінці я зберіг DataFrame як CSV файли, готові до подальшого аналізу та візуалізації.
### Подолання труднощів
* Автентифікація в хмарі: Хмарне середовище (PythonAnywhere) створювало певні труднощі з автентифікацією, які я вирішував через вручну здійснюваний процес авторизації.
* Обмеження на кількість запитів: Я подолав обмеження на кількість запитів API Spotify, впровадивши експоненціальну відкату та пакетні методи.
* Недоступні треки: Я систематично виявляв і реєстрував недоступні треки для подальшого розслідування.
Це дослідження Spotify API та підготовка даних надали мені знання та інструменти для аналізу своїх слухацьких звичок, виявлення патернів та отримання інсайтів щодо моїх музичних уподобань.
## Прогнозування пісень на основі даних Spotify: Підхід машинного навчання
Цей скрипт поринає в світ музики та науки про дані, з метою передбачити популярність пісень — конкретно, тих, які я можу полюбити — за допомогою методів машинного навчання, застосованих до даних Spotify.
### Дані: Серце справи
Подорож починається з даних, які є життєво важливими для будь-якого проекту машинного навчання. У цьому випадку дані складаються з різних метрик треків Spotify, включаючи аудіофункції, такі як танцювальність (danceability), енергія (energy) та темп (tempo), а також інша важлива інформація, така як кількість прослуховувань та можливу популярність артиста. Ці дані можуть бути отримані через BigQuery, потужне сховище даних Google Cloud, або з файлів, збережених на Google Cloud Storage (GCS).
### Попередня обробка: Підготовка даних до дії
Сирі дані рідко готові для безпосереднього використання алгоритмами машинного навчання. Їм часто потрібно пройти попередню обробку для забезпечення їх якості та сумісності.
Цей скрипт виконує кілька важливих кроків попередньої обробки даних:
- **Агрегація:** Дані групуються за назвою треку, агрегуючи інформацію, таку як загальний час прослуховування, середній час прослуховування та жанри, пов'язані з кожним треком.
- **Створення нових ознак:** Створюються нові ознаки на основі існуючих, щоб потенційно покращити ефективність моделі. Наприклад, загальний час прослуховування перетворюється в тривалість сесії в годинах, і додається прапорець для позначення того, чи була сесія прослуховування довшою за дві години.
- **Масштабування ознак:** Числові ознаки масштабуются за допомогою техніки, яка називається стандартизацією. Це гарантує, що всі ознаки мають подібний діапазон значень, запобігаючи домінуванню ознак з більшими значеннями в процесі навчання моделі.
- **Розподіл даних:** Набір даних розподіляється на тренувальний та тестовий набори. Тренувальний набір використовується для навчання моделі машинного навчання, а тестовий набір утримується для оцінки ефективності моделі на невідомих даних.
- **Кодування міток:** Імена артистів, які є цільовою змінною (те, що ми намагаємося передбачити), кодуються в числові мітки за допомогою `LabelEncoder`. Це необхідно, оскільки багато алгоритмів машинного навчання вимагають числових вхідних даних.
- **Обробка неподтримуваних типів даних:** Будь-які ознаки з неподтримуваними типами даних (наприклад, текст чи категоріальні дані) перетворюються в числові представлення за допомогою Label Encoding.
- **Імпутація відсутніх значень:** Відсутні значення в наборі даних обробляються за допомогою техніки імпутації, коли вони замінюються оцінковими значеннями (наприклад, середнім значенням стовпця).
- **Конвертація типів даних:** Усі ознаки перетворюються в єдиний тип даних (`float64`), щоб забезпечити сумісність з алгоритмом машинного навчання.
- **Балансування класів:** Якщо в наборі даних є дисбаланс (наприклад, більше неуспішних пісень, ніж хітів), застосовуються такі техніки, як SMOTE-Tomek для балансування класів та запобігання того, щоб модель була схильна до переважного класу.
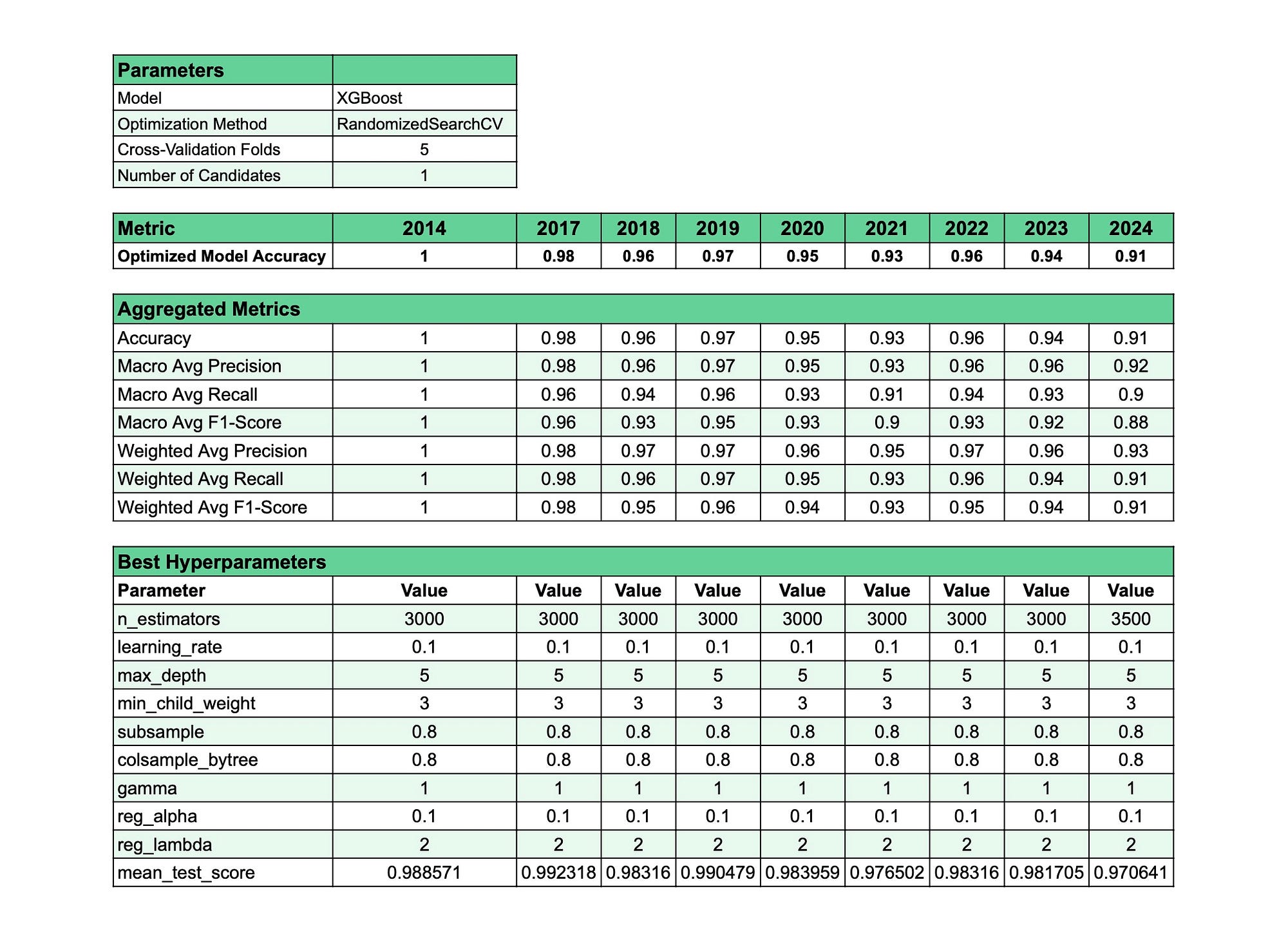
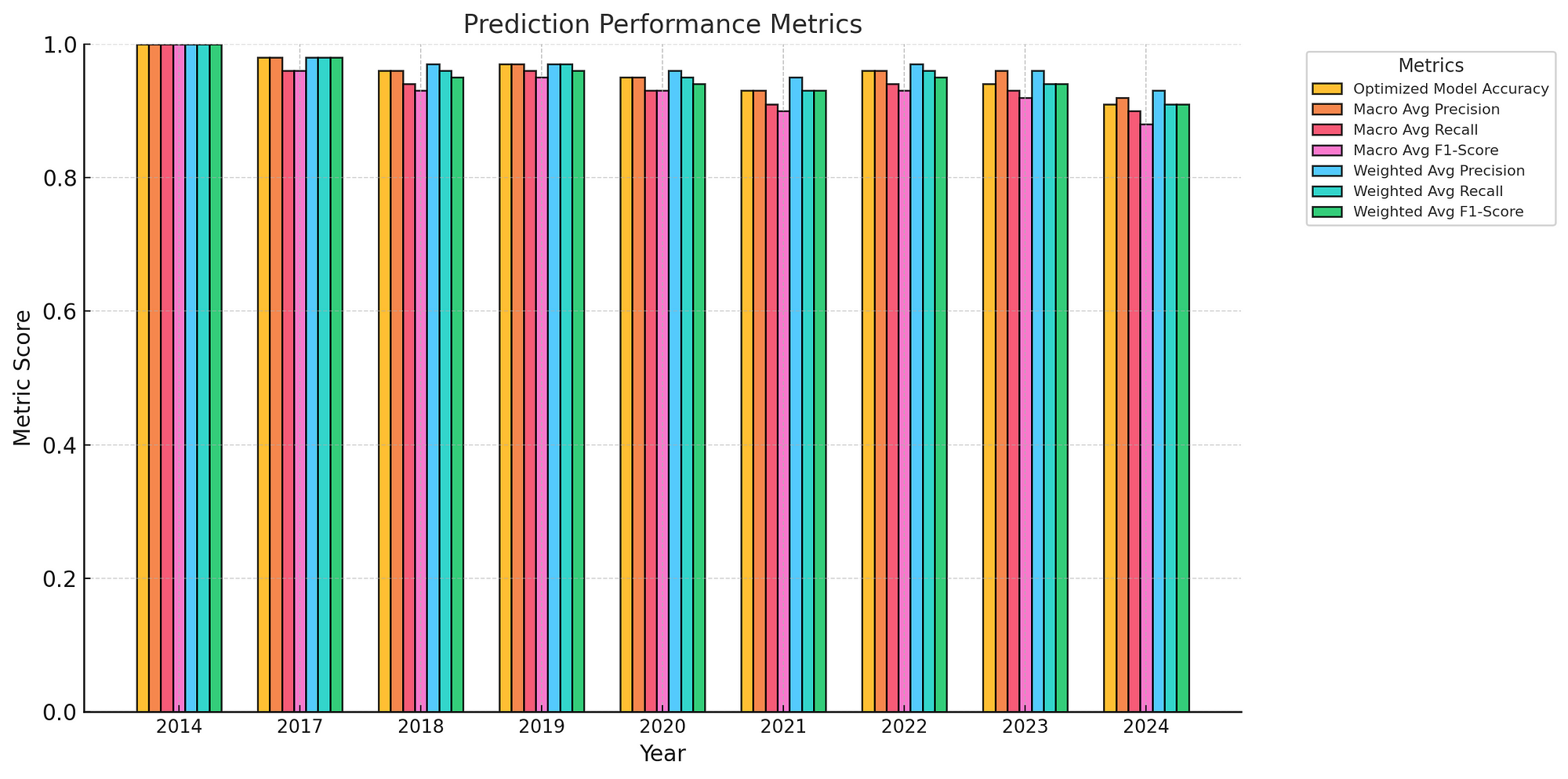
## Навчання моделі: Процес навчання
Після того, як дані підготовлені, скрипт переходить до навчання моделі. Для цього обирається класифікатор XGBoost. XGBoost — це потужний алгоритм градієнтного бустингу, відомий своєю високою точністю та ефективністю у задачах класифікації. Скрипт використовує `RandomizedSearchCV` для пошуку найкращих гіперпараметрів для моделі XGBoost. Це включає в себе дослідження різних комбінацій значень гіперпараметрів та оцінку їх ефективності за допомогою крос-валідації. Модель тренується на перепропорційованих тренувальних даних, а її ефективність оцінюється за допомогою таких метрик, як точність (accuracy) та F1-міра (F1-score).
## Оцінка та збереження: Оцінка та збереження моделі
Після того, як модель навчена, її ефективність оцінюється на відкладеному тестовому наборі. Метрики, такі як точність та звіт про класифікацію (classification report), надають розуміння того, як добре модель узагальнюється на невідомих даних. Найкраща модель, разом з її прогнозами та відповідними метриками, зберігається для подальшого використання або розгортання. Скрипт також ідентифікує та відображає найкращі набір гіперпараметрів, що може бути корисним для подальшого аналізу або оптимізації.
## В суті
Цей скрипт демонструє типовий робочий процес машинного навчання, підкреслюючи важливість попередньої обробки даних, створення нових ознак, вибору моделі, налаштування гіперпараметрів та оцінки. Застосовуючи ці техніки до даних Spotify, він намагається передбачити важливу характеристику "хітової" пісні, даючи уявлення про потенціал науки про дані у розумінні та прогнозуванні музичних тенденцій.
Перекладено з: [Spotify Wonderland](https://groundcontrolcharles.medium.com/spotify-wonderland-381f69eff508)